데이터 분석
Beautiful Soup 사용
jaewpark
2024. 8. 5. 11:41
설치
pip install beautifulsoup4
conda install beautifulsoup4
사용
html 개체로부터 Soup 만들기
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc)
print(soup.prettify()) # 객체의 내포된 데이터 구조를 보여줌
xml 개체로부터 Soup 만들기
lxml이 설치되어 있어야 한다.
설치는 위에서 BeautifulSoup를 설치하는 것처럼 라이브러리 이름만 변경하면 된다.
from bs4 import BeautifulSoup
soup = BeautifulSoup(xml_doc, 'xml')
메서드
find, find_all
find()는 해당 이름의 첫 번째 태그만 반환한다.find_all()은 해당 태그를 모두 가져올 수 있다.
find_all()은 매개변수를 넣지 않는다면 해당 태그를 모두 불러올 수 있다.
# find
soup.a
soup.find('a')
# <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
# find_all
soup.find_all('a')
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]find 을 통해 id, class 등 상세한 검색을 할 수 있다.find_all 또한 동일하다
soup.find('ul', class_='content')
soup.find('div', id='section1')
soup.find('a', href='http://example.com/elsie')
soup.find('a', string='tillie') # http://example.com/tillie
a_tag = soup.find('a', attrs={'class': 'sister', 'id': 'link2'})
print(a_tag.text)
select, select_one
css 를 이용한 검색 방법이다.
# a 태그에서 attribute로 href를 가지고 있는 것을 추출
soup.select_one('a[href]')
# 클래스가 `info_rating`인 요소의 자손 중 클래스가 `yes_b`인 모든 요소를 선택
soup.select(".info_rating .yes_b")
name
해당 태그의 이름을 반환한다.
soup.a.name
# 'a'
string
태그에 하위 항목이 하나만 있고 NavigableString인 경우 사용 가능하다.
head_tag.contents
# [<title>The Dormouse's story</title>]
head_tag.string
# 'The Dormouse's story'
text
해당 태그와 모든 자손 태그의 텍스트 노드를 모두 연결하여 반환한다.
html_doc = """
<div>
<p class="example">This is <b>bold</b> text.</p>
</div>
"""
soup = BeautifulSoup(html_doc, 'lxml')
# 'p' 태그 선택
p_tag = soup.find('p', class_='example')
# 'string' 속성 사용
print(p_tag.string) # None
# 'text' 속성 사용
print(p_tag.text) # This is bold text.
활용해보기 1
xml_file 내 있는 item 원소들을 테이블 형식으로 만들기
xml_file ="""
<response>
<header>
<resultCode>00</resultCode>
<resultMsg>NORMAL SERVICE.</resultMsg>
</header>
<body>
<numOfRows>10</numOfRows>
<pageNo>1</pageNo>
<totalCount>3696</totalCount>
<items>
<item> ... </item>
<item> ... </item>
<item> ... </item>
<item> ... </item>
<item> ... </item>
<item> ... </item>
<item> ... </item>
<item> ... </item>
<item> ... </item>
<item> ... </item>
</items>
</body>
</response>
"""
soup = BeautifulSoup(xml_doc, 'xml')
# soup.item.find_all() : soup에서 item의 내부 태그들을 리스트로 변환
# element : 태그가 포함된 정보를 반복문으로 하나씩 추출
# element.name : 태그의 이름만 추출
# dictionary : item 내 태그들을 key, 빈 배열을 value로 설정
dictionary = {element.name: [] for element in soup.item.find_all()}
# items : items 태그 내에 있는 item 태그로 되어있는 원소들이 들어간 배열
items = soup.items.find_all('item')
# item을 하나씩 추출
# setdefault를 이용하여 표현하면 코드가 더 줄어든다.
for item in items:
# item 내 태그들을 하나씩 추출
for element in item.find_all():
tag = element.name # 태그
value = element.string # 내용
dictionary[tag].append(value)
활용해보기 2
yes24 베스트 탭의 책 정보들을 수집하기
import requests
import pandas as pd
from bs4 import BeautifulSoup as bs
import re
domain = "https://www.yes24.com"
url = f"{domain}/Product/Category/BestSeller"
payload = dict(CategoryNumber="001", pageNumber=1, pageSize=24)
r = requests.get(url, params=payload)
soup = bs(r.text, "lxml")
books_info = soup.find_all("div", class_="itemUnit")
books = []
for book in books_info:
type = (
book_type.text[1:-1]
if (book_type := book.select_one(".info_name .gd_res"))
else None
)
name = (
book_name.text
if (book_name := book.select_one(".info_name .gd_name"))
else None
)
link = (
book_link
if (book_link := domain + book.select_one(".info_name .gd_name").get("href"))
else None
)
publish = (
book_publish.text if (book_publish := book.select_one(".info_pub a")) else None
)
date = book_date.text if (book_date := book.select_one(".info_date")) else None
price = (
book_price.text
if (book_price := book.select_one(".info_price .yes_b"))
else None
)
point = (
book_point.next_sibling[:-1]
if (book_point := book.select_one(".info_price .ico_point"))
else None
)
sale_number = (
book_sale_number.text.strip().split()[1]
if (book_sale_number := book.select_one(".info_rating .saleNum"))
else None
)
review_count = (
"".join(re.findall(r"\d+", book_review_count.text))
if (book_review_count := book.select_one(".info_rating .rating_rvCount a"))
else None
)
review_grade = (
book_review_grade.text
if (book_review_grade := book.select_one(".info_rating .rating_grade .yes_b"))
else None
)
auths = {}
book_auths = book.select_one(".info_auth")
for book_auth in book_auths.text.split("/"):
parts = [part[::-1] for part in book_auth[::-1].strip().split(" ", 1)]
auths.setdefault(parts[0], parts[1])
book_dict = {
"type": type,
"name": name,
"link": link,
"auths": auths,
"publish": publish,
"date": date,
"price": price,
"point": point,
"sale_number": sale_number,
"review_count": review_count,
"review_grade": review_grade,
}
books.append(book_dict)
print(books)활용해보기 3
KIND한국거래소 전자공시에서 상장법인 가져오기
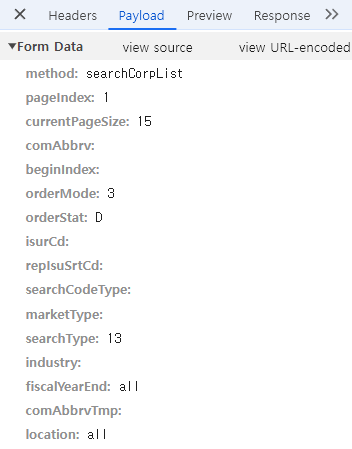
링크 의 개발자 모드에서는 값을 가져올 수 없는 부분이 있다.
이런 경우에는 아래의 방법으로 가져올 수 있는지 확인하면 된다.
- 개발자 모드(Chrome F12)
- Network
Fetch/XHR- 해당 페이지를 새로고침해서 좌측 파일을 확인
Preview로 원하는 정보인지 확인Payload로params확인- view source를 눌러 쿼리 확인

pandas 패키지 내 pd.read_html로 내부에 Table을 가져오는 메서드가 존재
대신 컬럼명이 안들어가고, 세부적인 값을 변경하기에 까다롭다.