크롤링 그리고 데이터 저장까지
진행 단계
3단계로 데이터를 저장할 수 있습니다.
- 데이터 수집 : Selenium
- 데이터 정제 및 모델링 : Beautiful Soup
- 데이터 저장 : MySQL, Pandas
데이터 수집
Selenium을 사용하여 html 데이터를 가져오려고 합니다.
예시에서는 네이버 증권을 접속하도록 하겠습니다.
Selenium 패키지 사용
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
크롬 브라우저 설정
더 자세한 설정은 이전 포스팅을 참고하면 됩니다.
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--disable-extensions') # 확장 프로그램 비활성화
chrome_options.add_argument('--headless') # 브라우저 창을 띄우지 않음 (백그라운드 실행, 선택사항)
크롬 브라우저 사용
브라우저를 최대화하는 설정 chrome_options.add_argument('--start-maximized')이 있지만,
작성된 코드를 노트북, 데스크탑 등 다양한 환경에서 동작하게 한다면 동일한 환경으로 만들기 위해서는 윈도우 사이즈를 직접 설정하는 것이 좋습니다.
# 크롬 드라이버 설치 및 브라우저 열기
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()), options=chrome_options)
# 윈도우 사이즈 설정
driver.set_window_size(1920, 1080)
# url 접속
url = "https://finance.naver.com/"
driver.get(url)
크롬 브라우저 제어
입력창에 키워드 입력 및 버튼 클릭의 상호 작용을 할 수 있습니다.
그리고 데이터(html) 을 가져올 수 있습니다.
# 검색 창 입력
search_box = driver.find_element(By.ID, "stock_items")
search_box.send_keys("SK하이닉스")
# 검색 버튼 클릭
search_button = driver.find_element(By.CSS_SELECTOR, "#header > div.header_area > div > div.right_area > div.search_area > form > button")
search_button.click()
# html 정보
page_html = driver.page_source
Enter 키로도 검색할 수 있는 경우에는 버튼 클릭이 아닌 search_box.send_keys(Keys.ENTER)을 사용합니다.
코드 분리
네이버 증권 사이트에서 여러 기업을 검색을 한다면 브라우저에서 동작을 하도록 할테니,driver 그리고 브라우저의 동작을 분리하면 코드가 읽기 쉽습니다.
코드를 좀더 읽기 쉽게 아래와 같이 변경할 수 있습니다.
더 나은 코드로 변경될 수 있으니 정답은 아닙니다.
# ChromeDriver.py
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
def chrome_driver(url):
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--disable-extensions')
chrome_options.add_argument('--headless')
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()), options=chrome_options)
driver.set_window_size(1920, 1080)
driver.get(url)
return driver
def get_html(company_name):
search_box = driver.find_element(By.ID, "stock_items")
search_box.send_keys(company_name+Keys.ENTER)
return driver.page_source
def execute():
url = "https://finance.naver.com/"
driver = chrome_driver(url)
company_names = [ ... ]
for company_name in companys_names:
page_html = get_html(company_name)
# 데이터를 정제하는 코드 작성
데이터 정제 및 수집
가져오고자 하는 데이터가 테이블 형식이라면, Beautiful Soup을 사용하지 않고도 데이터를 가져올 수 있습니다. 하지만 모든 데이터가 그렇지 않으니 데이터를 정제하고 수집하는 것을 설명하고자 합니다.
Beautiful Soup를 이용하여 tag, id, class 를 이용하여 해당 코드만 가져올 수 있습니다.
예시에서 .rate_info 의 태그를 가져와서 내부에 담긴 정보를 가져와서 데이터를 정제합니다.
# beautiful 설정
from bs4 import BeautifulSoup as bs
soup = bs(html_doc)
기업의 주가 정보 가져오기
# 오늘자 특정 기업의 주가 정보
data = [datetime.date.today(), company_name]
# 원하는 정보가 담긴 Tag
rate_info = soup.find(class_="rate_info")
# 현가
current_price = rate_info.select_one(".no_today .blind").string
data.append(current_price)
# 전일 대비 (Price Change)
price_change_sign = "+" if rate_info.select_one(".no_exday .ico").string == "상승" else "-"
price_change = rate_info.select_one(".no_exday .blind").string
data.append(price_change_sign + price_change)
# 전일 종가 (Previous Close Price)
# 시가 (Opening Price)
# 고가 (High Price)
# 저가 (Low Price)
# 거래량 (Trading Volume)
# 거래대금 (Trading Value)
for price_info in soup.select(".no_info td"):
price = price_info.find(class_="blind").string
data.append(price)
더 다양한 코드 및 메서드의 내용은 이전 포스팅에서 확인할 수 있습니다.
데이터 저장
MySQL에 저장하기 위해 pandas를 이용해서 딕셔너리가 담긴 배열 혹은 2차원 배열 등을 데이터프레임 형태로 변환하여 저장합니다.
데이터프레임으로 만들기 위해서는 행과 열의 개수가 동일한 객체여야 합니다.
import pandas as pd
from sqlalchemy import create_engine, text
데이터프레임 생성
정해진 컬럼명으로 데이터프레임 생성합니다.
columns = [
'date',
'company_name',
'price',
'Price Change',
'Previous Close Price',
'Opening Price',
'High Price',
'Low Price',
'Trading Volume',
'Trading Value'
]
df = pd.DataFrame(data, columns=columns)
데이터베이스 생성
데이터베이스의 정보는 보안을 위해 env를 따로 만들어서 값을 가져오는 전략을 사용합니다.dotenve 라는 패키지가 있지만, 실행파일(exe 파일)로 만드는 과정에서 동작을 안하는 이슈가 발생하여 env.py를 사용하여 값을 가져오는 방식을 사용했습니다.
engine.connect() 은 명시적으로 표현했을 뿐, 사용하지 않아도 됩니다.create_engine()와 ORM을 사용할 때 SQLAlchemy는 자동으로 연결 풀을 관리하고 필요한 경우 연결을 열고 닫습니다.
# 데이터베이스 엔진 생성
conn = create_engine(f"{env.db}+{env.dbtype}://{env.id}:{env.pw}@{env.host}")
conn = engine.connect()
conn.execute(text(f"CREATE DATABASE IF NOT EXISTS {env.database}"))
conn.close()
테이블 저장
append를 사용하면 해당 데이터를 추가합니다.replace를 사용하면 해당 데이터로 변경합니다.
engine = create_engine(f"{env.db}+{env.dbtype}://{env.id}:{env.pw}@{env.host}/{env.database}")
df.to_sql('stock_company_info', con=engine, if_exists='append', index=False)
테이블명이 계속 변경된다면 메서드로 분리하여 사용하면 됩니다.
MySQL 확인
지금까지의 코드가 제대로 들어가 있는지 MySQL로 확인

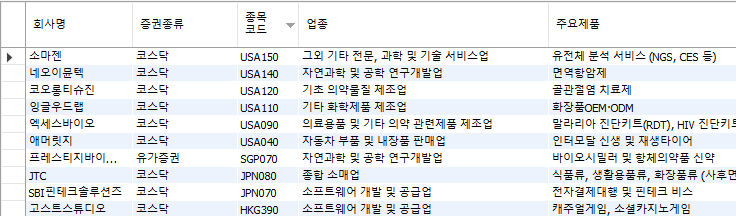
종목코드는 숫자로만 이뤄질 거라 생각했지만, 지역이 외국인 경우에는 국가명+코드로 이루어져 있기에 오류가 발생했었습니다.
크롤링을 하다보면 API 통신과 같이 값이 없다는 걸 전제하에 진행해야 합니다.
값이 없다면 None 혹은 0 과 같은 데이터를 넣어줍니다.
값 자체가 당연하다 여기지 않는 게 중요합니다.
정보가 누락된 데이터를 데이터 프레임으로 변경하면 컬럼 개수가 맞지 않아 에러가 발생하는 경우가 존재합니다.